Installation & Configuration¶
Getting Started¶
Superset is tested against Python 2.7 and Python 3.4.
Airbnb currently uses 2.7.* in production. We do not plan on supporting
Python 2.6.
OS dependencies¶
Superset stores database connection information in its metadata database.
For that purpose, we use the cryptography Python library to encrypt
connection passwords. Unfortunately this library has OS level dependencies.
You may want to attempt the next step (“Superset installation and initialization”) and come back to this step if you encounter an error.
Here’s how to install them:
For Debian and Ubuntu, the following command will ensure that the required dependencies are installed:
sudo apt-get install build-essential libssl-dev libffi-dev python-dev python-pip libsasl2-dev libldap2-dev
For Fedora and RHEL-derivatives, the following command will ensure that the required dependencies are installed:
sudo yum upgrade python-setuptools
sudo yum install gcc gcc-c++ libffi-devel python-devel python-pip python-wheel openssl-devel libsasl2-devel openldap-devel
OSX, system python is not recommended. brew’s python also ships with pip
brew install pkg-config libffi openssl python
env LDFLAGS="-L$(brew --prefix openssl)/lib" CFLAGS="-I$(brew --prefix openssl)/include" pip install cryptography==1.7.2
Windows isn’t officially supported at this point, but if you want to
attempt it, download get-pip.py, and run python get-pip.py which may need admin access. Then run the following:
C:\> pip install cryptography
# You may also have to create C:\Temp
C:\> md C:\Temp
Python virtualenv¶
It is recommended to install Superset inside a virtualenv. Python 3 already ships virtualenv, for Python 2 you need to install it. If it’s packaged for your operating systems install it from there otherwise you can install from pip:
pip install virtualenv
You can create and activate a virtualenv by:
# virtualenv is shipped in Python 3 as pyvenv
virtualenv venv
. ./venv/bin/activate
On windows the syntax for activating it is a bit different:
venv\Scripts\activate
Once you activated your virtualenv everything you are doing is confined inside the virtualenv.
To exit a virtualenv just type deactivate.
Python’s setup tools and pip¶
Put all the chances on your side by getting the very latest pip
and setuptools libraries.:
pip install --upgrade setuptools pip
Superset installation and initialization¶
Follow these few simple steps to install Superset.:
# Install superset
pip install superset
# Create an admin user (you will be prompted to set username, first and last name before setting a password)
fabmanager create-admin --app superset
# Initialize the database
superset db upgrade
# Load some data to play with
superset load_examples
# Create default roles and permissions
superset init
# Start the web server on port 8088, use -p to bind to another port
superset runserver
# To start a development web server, use the -d switch
# superset runserver -d
After installation, you should be able to point your browser to the right hostname:port http://localhost:8088, login using the credential you entered while creating the admin account, and navigate to Menu -> Admin -> Refresh Metadata. This action should bring in all of your datasources for Superset to be aware of, and they should show up in Menu -> Datasources, from where you can start playing with your data!
Please note that gunicorn, Superset default application server, does not work on Windows so you need to use the development web server. The development web server though is not intended to be used on production systems so better use a supported platform that can run gunicorn.
Configuration behind a load balancer¶
If you are running superset behind a load balancer or reverse proxy (e.g. NGINX
or ELB on AWS), you may need to utilise a healthcheck endpoint so that your
load balancer knows if your superset instance is running. This is provided
at /health which will return a 200 response containing “OK” if the
webserver is running.
If the load balancer is inserting X-Forwarded-For/X-Forwarded-Proto headers, you should set ENABLE_PROXY_FIX = True in the superset config file to extract and use the headers.
Configuration¶
To configure your application, you need to create a file (module)
superset_config.py and make sure it is in your PYTHONPATH. Here are some
of the parameters you can copy / paste in that configuration module:
#---------------------------------------------------------
# Superset specific config
#---------------------------------------------------------
ROW_LIMIT = 5000
SUPERSET_WORKERS = 4
SUPERSET_WEBSERVER_PORT = 8088
#---------------------------------------------------------
#---------------------------------------------------------
# Flask App Builder configuration
#---------------------------------------------------------
# Your App secret key
SECRET_KEY = '\2\1thisismyscretkey\1\2\e\y\y\h'
# The SQLAlchemy connection string to your database backend
# This connection defines the path to the database that stores your
# superset metadata (slices, connections, tables, dashboards, ...).
# Note that the connection information to connect to the datasources
# you want to explore are managed directly in the web UI
SQLALCHEMY_DATABASE_URI = 'sqlite:////path/to/superset.db'
# Flask-WTF flag for CSRF
CSRF_ENABLED = True
# Set this API key to enable Mapbox visualizations
MAPBOX_API_KEY = ''
This file also allows you to define configuration parameters used by Flask App Builder, the web framework used by Superset. Please consult the Flask App Builder Documentation for more information on how to configure Superset.
Please make sure to change:
- SQLALCHEMY_DATABASE_URI, by default it is stored at ~/.superset/superset.db
- SECRET_KEY, to a long random string
Database dependencies¶
Superset does not ship bundled with connectivity to databases, except for Sqlite, which is part of the Python standard library. You’ll need to install the required packages for the database you want to use as your metadata database as well as the packages needed to connect to the databases you want to access through Superset.
Here’s a list of some of the recommended packages.
| database | pypi package | SQLAlchemy URI prefix |
|---|---|---|
| MySQL | pip install mysqlclient |
mysql:// |
| Postgres | pip install psycopg2 |
postgresql+psycopg2:// |
| Presto | pip install pyhive |
presto:// |
| Oracle | pip install cx_Oracle |
oracle:// |
| sqlite | sqlite:// |
|
| Redshift | pip install sqlalchemy-redshift |
postgresql+psycopg2:// |
| MSSQL | pip install pymssql |
mssql:// |
| Impala | pip install impyla |
impala:// |
| SparkSQL | pip install pyhive |
jdbc+hive:// |
| Greenplum | pip install psycopg2 |
postgresql+psycopg2:// |
| Athena | pip install "PyAthenaJDBC>1.0.9" |
awsathena+jdbc:// |
| Vertica | pip install
sqlalchemy-vertica-python |
vertica+vertica_python:// |
| ClickHouse | pip install
sqlalchemy-clickhouse |
clickhouse:// |
Note that many other database are supported, the main criteria being the
existence of a functional SqlAlchemy dialect and Python driver. Googling
the keyword sqlalchemy in addition of a keyword that describes the
database you want to connect to should get you to the right place.
(AWS) Athena¶
This currently relies on an unreleased future version of PyAthenaJDBC. If you’re adventurous or simply impatient, you can install directly from git:
pip install git+https://github.com/laughingman7743/PyAthenaJDBC@support_sqlalchemy
The connection string for Athena looks like this
awsathena+jdbc://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&...
Where you need to escape/encode at least the s3_staging_dir, i.e.,
s3://... -> s3%3A//...
Caching¶
Superset uses Flask-Cache for
caching purpose. Configuring your caching backend is as easy as providing
a CACHE_CONFIG, constant in your superset_config.py that
complies with the Flask-Cache specifications.
Flask-Cache supports multiple caching backends (Redis, Memcached, SimpleCache (in-memory), or the local filesystem). If you are going to use Memcached please use the pylibmc client library as python-memcached does not handle storing binary data correctly. If you use Redis, please install the redis Python package:
pip install redis
For setting your timeouts, this is done in the Superset metadata and goes
up the “timeout searchpath”, from your slice configuration, to your
data source’s configuration, to your database’s and ultimately falls back
into your global default defined in CACHE_CONFIG.
Deeper SQLAlchemy integration¶
It is possible to tweak the database connection information using the
parameters exposed by SQLAlchemy. In the Database edit view, you will
find an extra field as a JSON blob.
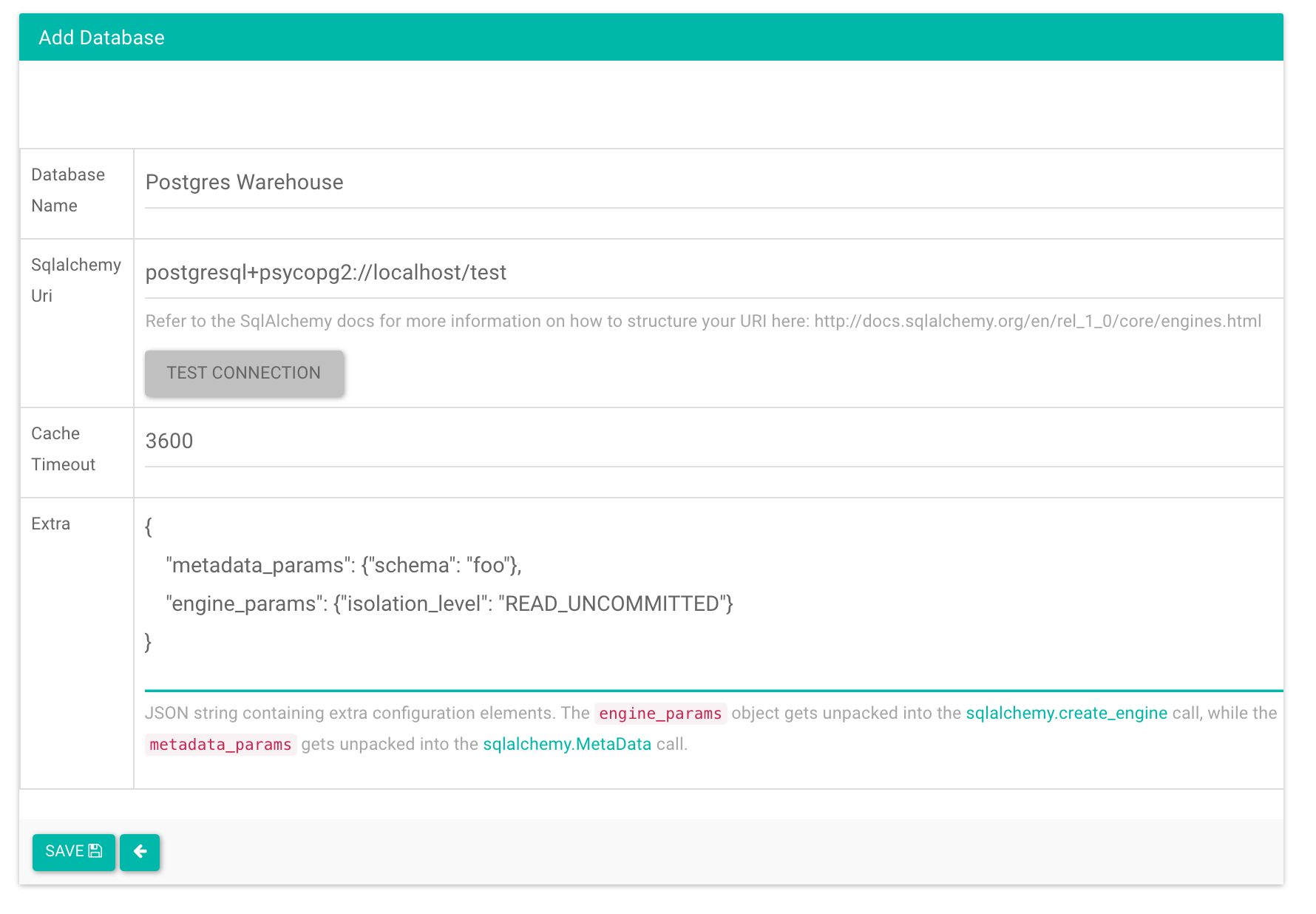
This JSON string contains extra configuration elements. The engine_params
object gets unpacked into the
sqlalchemy.create_engine call,
while the metadata_params get unpacked into the
sqlalchemy.MetaData call. Refer to the SQLAlchemy docs for more information.
Schemas (Postgres & Redshift)¶
Postgres and Redshift, as well as other database, use the concept of schema as a logical entity on top of the database. For Superset to connect to a specific schema, there’s a schema parameter you can set in the table form.
SSL Access to databases¶
This example worked with a MySQL database that requires SSL. The configuration
may differ with other backends. This is what was put in the extra
parameter
{
"metadata_params": {},
"engine_params": {
"connect_args":{
"sslmode":"require",
"sslrootcert": "/path/to/my/pem"
}
}
}
Druid¶
- From the UI, enter the information about your clusters in the
Admin->Clustersmenu by hitting the + sign. - Once the Druid cluster connection information is entered, hit the
Admin->Refresh Metadatamenu item to populate - Navigate to your datasources
Note that you can run the superset refresh_druid command to refresh the
metadata from your Druid cluster(s)
CORS¶
The extra CORS Dependency must be installed:
superset[cors]
The following keys in superset_config.py can be specified to configure CORS:
ENABLE_CORS: Must be set to True in order to enable CORSCORS_OPTIONS: options passed to Flask-CORS (documentation <http://flask-cors.corydolphin.com/en/latest/api.html#extension>)
MIDDLEWARE¶
Superset allows you to add your own middleware. To add your own middleware, update the ADDITIONAL_MIDDLEWARE key in
your superset_config.py. ADDITIONAL_MIDDLEWARE should be a list of your additional middleware classes.
For example, to use AUTH_REMOTE_USER from behind a proxy server like nginx, you have to add a simple middleware class to
add the value of HTTP_X_PROXY_REMOTE_USER (or any other custom header from the proxy) to Gunicorn’s REMOTE_USER
environment variable:
class RemoteUserMiddleware(object):
def __init__(self, app):
self.app = app
def __call__(self, environ, start_response):
user = environ.pop('HTTP_X_PROXY_REMOTE_USER', None)
environ['REMOTE_USER'] = user
return self.app(environ, start_response)
ADDITIONAL_MIDDLEWARE = [RemoteUserMiddleware, ]
Adapted from http://flask.pocoo.org/snippets/69/
Upgrading¶
Upgrading should be as straightforward as running:
pip install superset --upgrade
superset db upgrade
superset init
SQL Lab¶
SQL Lab is a powerful SQL IDE that works with all SQLAlchemy compatible databases. By default, queries are executed in the scope of a web request so they may eventually timeout as queries exceed the maximum duration of a web request in your environment, whether it’d be a reverse proxy or the Superset server itself.
On large analytic databases, it’s common to run queries that execute for minutes or hours. To enable support for long running queries that execute beyond the typical web request’s timeout (30-60 seconds), it is necessary to configure an asynchronous backend for Superset which consist of:
- one or many Superset worker (which is implemented as a Celery worker), and
can be started with the
superset workercommand, runsuperset worker --helpto view the related options - a celery broker (message queue) for which we recommend using Redis or RabbitMQ
- a results backend that defines where the worker will persist the query results
Configuring Celery requires defining a CELERY_CONFIG in your
superset_config.py. Both the worker and web server processes should
have the same configuration.
class CeleryConfig(object):
BROKER_URL = 'redis://localhost:6379/0'
CELERY_IMPORTS = ('superset.sql_lab', )
CELERY_RESULT_BACKEND = 'redis://localhost:6379/0'
CELERY_ANNOTATIONS = {'tasks.add': {'rate_limit': '10/s'}}
CELERY_CONFIG = CeleryConfig
To setup a result backend, you need to pass an instance of a derivative
of werkzeug.contrib.cache.BaseCache to the RESULTS_BACKEND
configuration key in your superset_config.py. It’s possible to use
Memcached, Redis, S3 (https://pypi.python.org/pypi/s3werkzeugcache),
memory or the file system (in a single server-type setup or for testing),
or to write your own caching interface. Your superset_config.py may
look something like:
# On S3
from s3cache.s3cache import S3Cache
S3_CACHE_BUCKET = 'foobar-superset'
S3_CACHE_KEY_PREFIX = 'sql_lab_result'
RESULTS_BACKEND = S3Cache(S3_CACHE_BUCKET, S3_CACHE_KEY_PREFIX)
# On Redis
from werkzeug.contrib.cache import RedisCache
RESULTS_BACKEND = RedisCache(
host='localhost', port=6379, key_prefix='superset_results')
Also note that SQL Lab supports Jinja templating in queries, and that it’s
possible to overload
the default Jinja context in your environment by defining the
JINJA_CONTEXT_ADDONS in your superset configuration. Objects referenced
in this dictionary are made available for users to use in their SQL.
JINJA_CONTEXT_ADDONS = {
'my_crazy_macro': lambda x: x*2,
}
Making your own build¶
For more advanced users, you may want to build Superset from sources. That would be the case if you fork the project to add features specific to your environment.:
# assuming $SUPERSET_HOME as the root of the repo
cd $SUPERSET_HOME/superset/assets
npm install
npm run build
cd $SUPERSET_HOME
python setup.py install
Blueprints¶
Blueprints are Flask’s reusable apps.
Superset allows you to specify an array of Blueprints
in your superset_config module. Here’s
an example on how this can work with a simple Blueprint. By doing
so, you can expect Superset to serve a page that says “OK”
at the /simple_page url. This can allow you to run other things such
as custom data visualization applications alongside Superset, on the
same server.
..code
from flask import Blueprint
simple_page = Blueprint('simple_page', __name__,
template_folder='templates')
@simple_page.route('/', defaults={'page': 'index'})
@simple_page.route('/<page>')
def show(page):
return "Ok"
BLUEPRINTS = [simple_page]